Update: a slide deck is now available as well - a presentation about IR in general and the axiomatic approach to neural IR models, given to MSc students as part of the Delft Deep Learning Colloqium 2019.
Introduction
Traditional retrieval models such as BM25 or language models have been engineered based on search heuristics that later have been formalized into so-called axioms.
One of the first axioms proposed is TFC1: given a single-term query w and two equally long documents, the retrieval score of the document with a higher frequency of w should be ranked higher.
The axiomatic approach to IR has shown that the effectiveness of a retrieval method is connected to its fulfillment of axioms. This approach enabled researchers to identify shortcomings in existing approaches and fix them. This requires a theoretical analysis of the retrieval formula, which in the case of BM25 and other classic retrieval models amounts to determining in what hyperparameter ranges certain axioms hold.
Diagnostic Datasets in Neural IR
Ideally, we employ a similar axiomatic approach to diagnose and fix neural IR models in order to reap the benefits deep learning has offered in other fields. However, as these models may contain millions of parameters, this is not feasible.
In our recently accepted ECIR 2019 paper (preprint):
@inproceedings{ECIR2019Axiomatic,
author = {D. Rennings and F. Moraes and C. Hauff},
title = {An Axiomatic Approach to Diagnosing Neural {IR} Models},
booktitle = {ECIR 2019},
pages = {489--503},
year = {2019}
}
which is the result of a Master thesis project, we propose a pipeline to create large-scale diagnostic datasets for IR, each engineered to fulfill one axiom. We execute our pipeline on the recently released question answering dataset WikiPassageQA (which contains over 4000 topics) and create diagnostic datasets for four axioms. Each diagnostic dataset contains more than 10K diagnostic instances, i.e. instances that fulfil a particular axiom.
Importantly, as in actual datasets we are unlikely to encounter instances that fit the existing axioms exactly (e.g. for TFC1 that would require finding pairs of documents that are exactly the same length and differ in their count of single-term query), we had to extend and relax the existing axioms to enable us to find diagnostic instances in existing datasets.
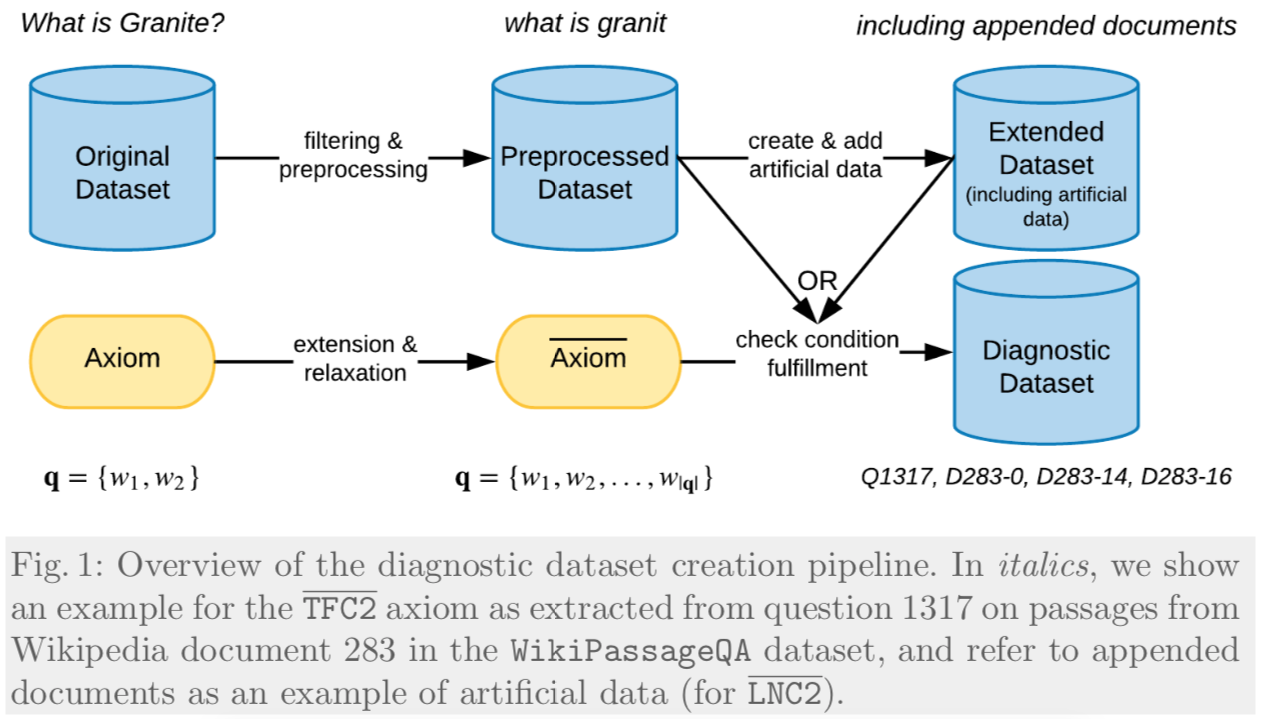
Once a diagnostic dataset is created, it can be employed on any neural IR model, it is thus a way to diagnose models in a model-agnostic manner. All we consider is how each trained model ranks the provided document instances. This in turn tells us to what extent a model has learnt the type of knowledge encoded in an axiom. As diagnostic datasets do not require relevance judgments, they can be extracted from almost any given set of queries and document corpus.
Findings
We empirically validate to what extent well-known deep IR models are able to realize the axiomatic pattern underlying the datasets. The table ![]() contains the main results of our work.
contains the main results of our work.
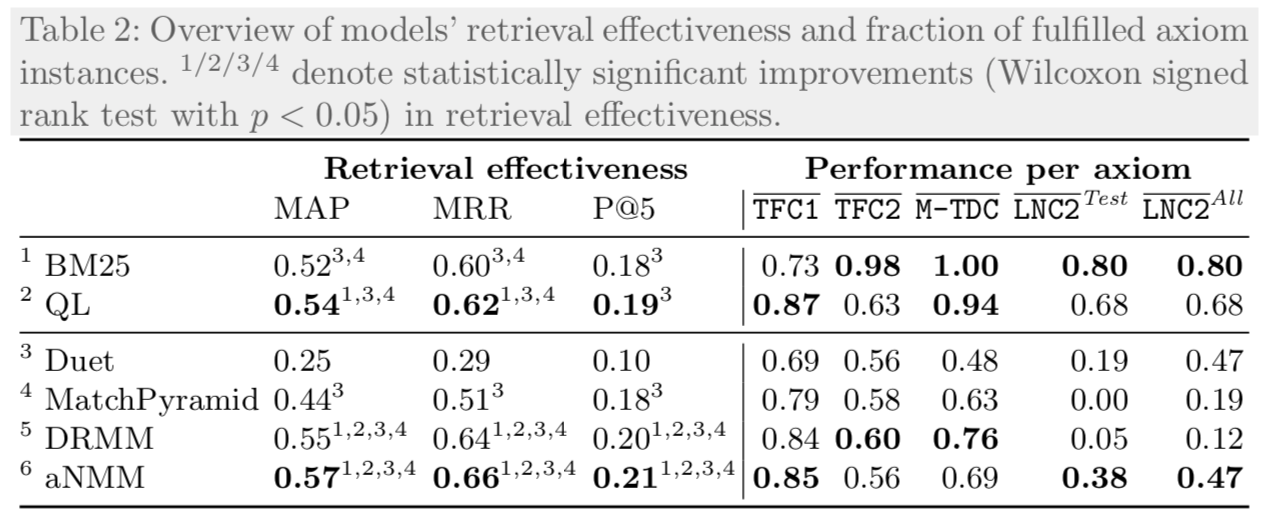
The first three result columns show the retrieval effectiveness of the various deep and non-deep approaches on the original WikiPassageQA dataset. BM25 and language modeling (QL) perform well, the deep models struggle to outperform them.
The performance per axiom columns contain the fraction of diagnostic instances that the models rank in the correct order (as dictated by the axiom). The classic retrieval models manage to produce correct rankings for most diagnostic instances, while the deep models lag behind. This is particularly apparent for axiom LNC2: it prescribes that over-penalizing long documents should be avoided; if a document is replicated k times, its retrieval status value should not be lower than that of its un-replicated variant.
What’s next
The obvious next step is to try to fix neural IR models so that they fulfil the diagnostic datasets to a better degree, either training data augmentation or the adaptation of their loss function. If that indeed also leads to higher retrieval effectiveness we can then go on with our work of diagnostic dataset creation and consider some more of the 20+ axioms proposed in the literature.