While today’s Web search engines are designed for single-user search, over the years research efforts have shown that complex information needs - which are explorative, open-ended and multi-faceted - can be answered more efficiently and effectively when searching in collaboration.
Collaborative search (and sensemaking) research has investigated techniques, algorithms and interface affordances to gain insights and improve the collaborative search process. It is not hard to imagine that the size of the group collaborating on a search task significantly influences the group’s behaviour and search effectiveness.
However, a common denominator across almost all existing studies is a fixed group size - usually either pairs, triads or in a few cases four users collaborating. Investigations into larger group sizes and the impact of group size dynamics on users’ behaviour and search metrics have so far rarely been considered - and when, then only in a simulation setup.
In our recently accepted Information Retrieval journal article (published some time in 2019, the preprint can be viewed here):
@article{IRJ2019ColSearchGroupSizes,
author = {Felipe Moraes, Kilian Grashoff and Claudia Hauff},
title = {On the Impact of Group Size on Collaborative Search Effectiveness},
journal = {Information Retrieval Journal},
year = {2019}
}
we took aim at this research gap and explored the following question: What is the impact of group size on collaborative search effectiveness?
First, we categorized previous research in a neat table:
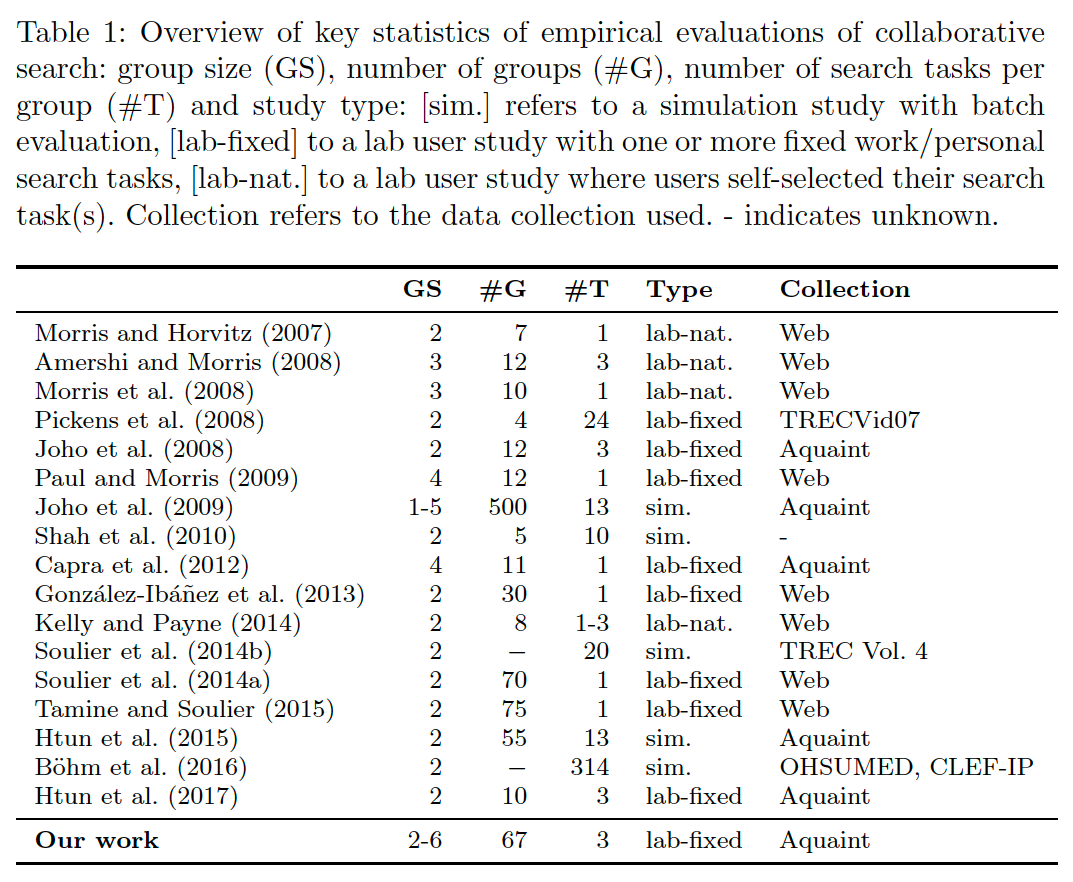
Evidently, user studies with collaborating pairs are the most popular. Few studies work with self-selected search tasks, the setup with a fixed set of search tasks is the most popular.
Our contributions
Through a large-scale user experiment (>300 participants) we investigated to what extent prior simulation findings on variable group sizes in collaborative search carry over to the real world. We made a number of contributions:
- First of all, we extended SearchX, our synchronous collaborative search framework with algorithmic mediation components as well as features enabling efficient use of SearchX for crowdsourcing studies, that we successfully deployed in a crowd-sourcing setup with hundreds of crowd-workers and different levels of user and task synchronisation.
- We found most prior simulation-based results on the impact of group size on behaviour and search effectiveness to not hold in our user study.
- Importantly, in our study - conducted across three difficult recall-oriented search topics - we do not observe diminishing returns (measured in recall) when scaling up group sizes from two to six collaborators. Our results indicate that a further scaling up of group sizes is feasible with existing collaborative search features and can potentially lead to new research avenues in the collaborative search space.
Our study
We investigated three search conditions, with various levels of collaborative features switched on:
- S-Single: Independent search with individual bookmarks and individual query history (no awareness, no division of labour).
- S-UI-Coll: S-Single + Shared saved documents, shared query history and collapsing of saved and excluded documents in the SERP (awareness, interface-level division of labour).
- S-UIAlg-Coll: S-UI-Coll + Shared relevance feedback (awareness, interface-level division of labour and system-level sharing of knowledge)
We used Aquaint as our corpus and selected three of the most difficult topics (=lowest recall achieved by automated search systems among all Aquaint topics): airport security, piracy and tax evasion indicted. Each crowd-worker (we used Prolific as our worker source) moved through the following workflow:
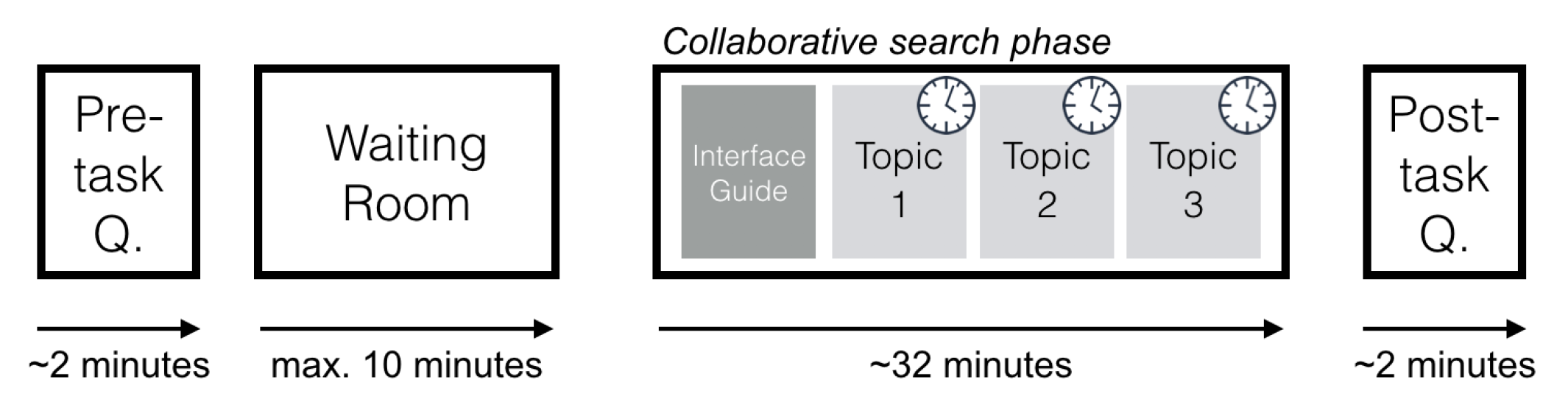
The hardest part turned out to be to get sufficiently many crowd-workers into a single experiment. Our goal was to collect data on four group sizes: 1, 2, 4 and 6. Since we are looking at synchronous collaborative search we needed our crowd-workers to wait in a virtual waiting room for some time to allow sufficiently many other workers to join the experiment. We added a game of snake to make it more appealing. After a maximum waiting time we started the experiment anyway - with however many workers were currently in the waiting room. We synced the movement of the group of workers through the three search tasks - after 10 minutes on the task, the workers that searched together were moved to the next search task.
Findings
The major findings of the work are aggregated in nine plots (since in practice we ended up with group sizes of 3 and 5 as well, we considered groups of 3&4 as well as groups of 5&6 workers as one group size). Here, we plot the average group recall for each topic and search variant computed in two-minute time intervals:
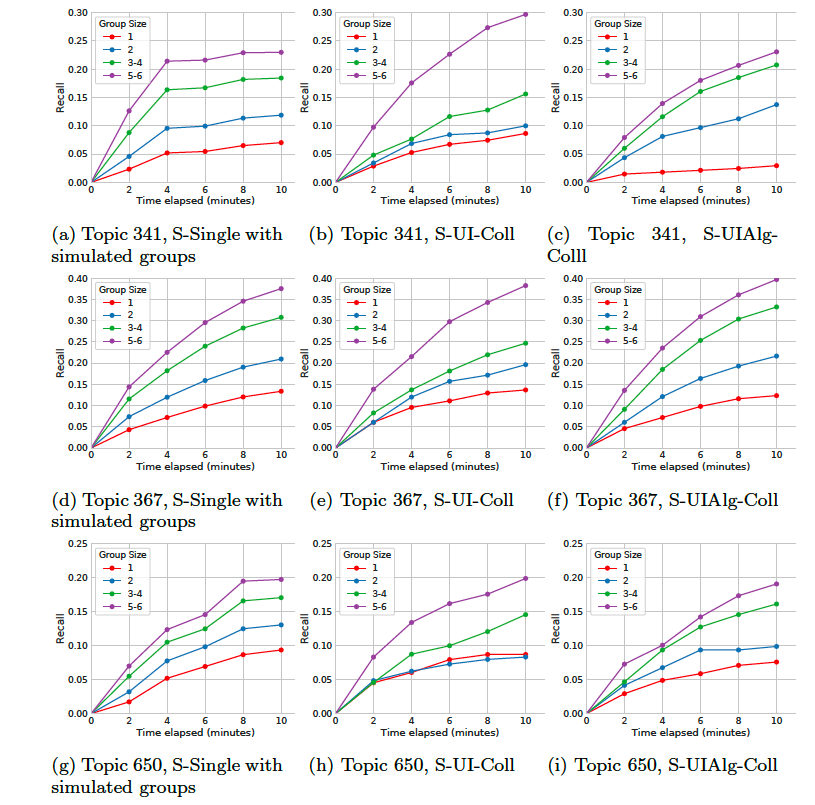
The four main observations are the following:
- For none of the topics, search variants and group size combination is the reported recall greater than 0.4, indicating the difficulty of the topics and the potential benefit an increasing collaborator pool could bring about.
- A larger group size leads to a larger recall level.
- We did not observe a synergy effect: pairs of collaborators were not more effective than two independent searchers whose results were aggregated (first plot column).
- The collaboration benefits do not diminish over time, they remain relatively constant and are not limited to the early minutes of the search session.
Where to go from here
Ideally, we continue scaling up the group size, in order to find the point of diminishing returns. However, this will not be possible in a crowd-sourcing setup, as it took a lot of sweat and programming to enable six crowd-workers who roughly start the task at the same time to remainn in sync throughout a thirty minute period. Any further studies in this direction have to be conducted in practical settings where we naturally have many participants working together (…sounds like something we ca do in a MOOC).
Algorithmic mediation is another direction we will pursue further; there is not a lot of research on this issue, as it is hard to get right and also hard to measure the effects in actual user studies. However, with the recent advances in all kinds of fields that happen to have access to a lot of data, we will continue in this direction as well.